Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising
† Equal contribution
Abstract
We introduce Time-to-Move (TTM), a training-free, plug-and-play framework that adds precise motion control to existing video diffusion models. While many prior methods require costly, model-specific fine-tuning, TTM requires no additional training or runtime cost and is compatible with any backbone. Our key insight is to use crude reference animations—such as “cut-and-drag” or depth-based reprojection—as coarse motion cues. Inspired by SDEdit, we adapt its mechanism to the video domain. We preserve appearance with image conditioning and introduce dual-clock denoising, a novel region-dependent strategy that enforces strong alignment in motion-specified regions while allowing flexibility elsewhere, balancing fidelity to user intent with natural dynamics. Moreover, compared to previous motion control methods, TTM enables joint control over both motion and appearance. Experiments demonstrate that it achieves comparable or superior performance to training-based baselines in both realism and motion fidelity.
Method Overview
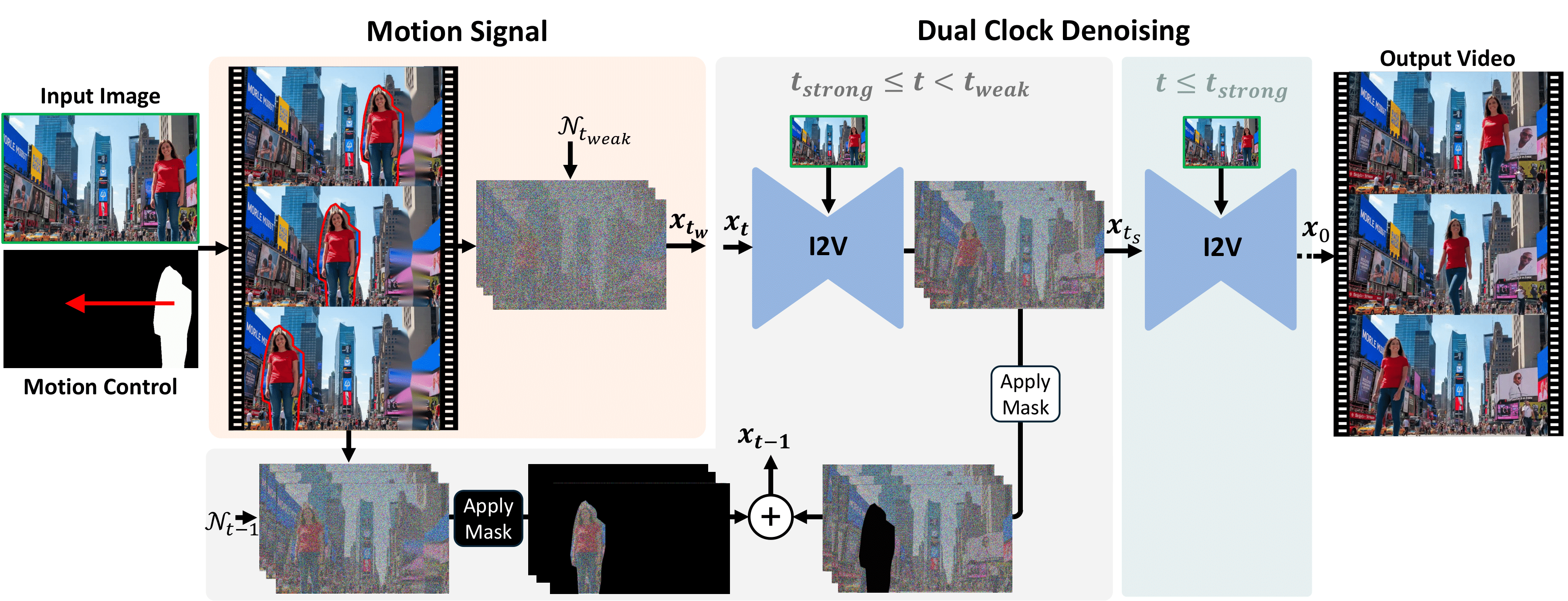
Time-to-Move (TTM) takes an input image and a user-specified motion, then automatically builds (i) a coarse warped reference video and (ii) a mask marking the controlled region. The image-to-video diffusion model is conditioned on the clean input image and initialized from a noisy version of the warped reference, anchoring appearance while injecting the intended motion. During sampling, dual-clock denoising is applied: lower noise inside the mask to enforce the commanded motion, higher noise elsewhere to enable it to evolve naturally. The result is a realistic video that preserves input details and faithfully follows the motion without extra training or architectural changes.
Dual-Clock Denoising
We present a region-dependent denoising strategy. Previous methods have limitations: SDEdit either suppresses dynamics in unmasked regions (at low noise levels) or drifts from the prescribed motion (at high levels). RePaint, on the other hand, enforces motion by overriding the foreground, but often introduces artifacts in uncontrolled regions and rigid motion in controlled regions. We propose a dual-clock method where masked regions follow the intended motion with strong fidelity, while the rest of the scene denoises more freely. This flexible approach yields realistic dynamics without artifacts.
Object Motion Control
Examples of user-specified object control. The user selects one or more regions of interest in an image using a mask and defines their trajectories. The masked regions are then dragged across all frames to produce a coarse, warped version of the intended object animation. Finally, TTM, integrated with the Wan 2.2 video model, generates a high-quality, dynamic video that accurately reflects the user’s intent.
Warped | Ours
Camera Motion Control
Examples of user-specified camera control from a single image. From any input image, we first estimate its depth and, given a user-defined camera trajectory, generate a warped video of the original frame as viewed from each new viewpoint. Any resulting holes are filled using nearest-neighbor colors, producing a coarse initial video that approximates the desired camera motion. Finally, TTM synthesizes a realistic video that accurately follows the specified camera path.
Warped | Ours
Warped | Ours
Warped | Ours
Warped | Ours
Motion and Appearance Control
Examples of user-specified object and appearance control. Our method enables both the insertion of new objects from outside the original image and the modification of an existing object’s appearance, such as changing its color or shape. Accordingly, a coarse, warped version of the intended object animation—including the desired appearance changes—is first generated and then fed into a TTM-based model that synthesizes the output video.
Warped | Ours
Warped | Ours
Warped | Ours
Warped | Ours
Warped | Ours
Warped | Ours
Qualitative Comparison: Object Control
Comparison of our method with the training-based state-of-the-art approach Go-with-the-Flow (GWTF) [1] on user-specified object control tasks.
Qualitative Comparison: Camera Control
Comparison of our method on user-specified camera control tasks.
Citation
@misc{singer2025timetomovetrainingfreemotioncontrolled,
title={Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising},
author={Assaf Singer and Noam Rotstein and Amir Mann and Ron Kimmel and Or Litany},
year={2025},
eprint={2511.08633},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.08633},
}
References
- , "Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise.", CVPR 2025.